Crawl Budget: Can You Afford to Ignore It?
Something that seems to be cropping up a lot recently throughout the world of SEO, Google and beyond, is Google’s “Crawl Budget.” The importance of it is certainly growing rapidly, and is keeping many SEO experts on their toes.
In this article, we take a brief look at what Google’s crawl budget is, and how to keep control of it moving forwards to improve SEO performance. So, without further ado…
What Is Crawl Budget?
Crawl budget, according to Google themselves, is gauged as the amount of time spent by search engines crawling a website on a day to day basis. Search engines do this, as they have to crawl as much of the internet as possible, so dividing budget between websites is the best way to achieve that.
So basically, Google (and other search engines) allocates a selection of URLs to be crawled and crawls them, based on how much time they have allocated to them. The number of URLs crawled can vary from anything between 10 and 10,000 URLs per day (give or take). Google defines crawl budget as “the number of URLs Googlebot can and wants to crawl.”
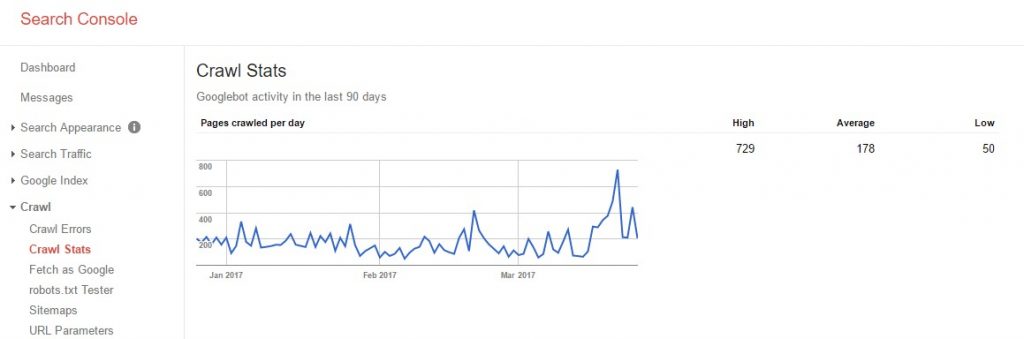
A good way to monitor how your website is crawled is to utilise the Crawl Stats tool in Google’s Search Console. In the example given below, we can see that the average daily crawl on “Website A” is 178 URLs per day. If we take this figure and times it by the number of days in a month, we end up with an estimated crawl budget of 5,518 pages per month.
So How Does This Impact You?
Have you ever noticed that despite multiple forced indexes in Google Search Console, aggressive link building and keyword rich anchor text on site, the page you’re working on doesn’t seem to be getting picked up in Google’s Index? This could mean that you are having issues with how your crawl budget is distributed on your website.
This delay in indexing could be happening for a number of reasons, however one of the more likely issues is that you have a page that Google is not prioritising, or deems the page value low after one or two crawls of the site.
It’s likely that this is because Google is taking longer to determine the value of a page, utilising RankBrain to learn what’s on the page, and then determining an output (ranking) for that specific page. With this in mind, we need to be certain that the pages we roll out are relevant, targeted and informative to both Google and the reader/customer, providing key information on what the page is about in the most efficient way possible.
The impact of this would mean that a poorly structured page, an ill-informed page or a page buried deep within your site is simply not going to pass the mark to achieve a good ranking. It’s more likely that there will be a demotion of the page once it’s been hit by GoogleBot more than once or twice due to the content being irrelevant or bloated.
We have to remember here, that Google allocates a specific crawl budget to a website, which in return will want to find quality and informative information that it feels is worthy of displaying in its results pages. Therefore, the page has to earn the best rankings it can, by providing the best information possible.
As an example, it’s particularly rare to see paginated pages fully opened up to Google, particularly those that breach 15 pages or higher. If Google was granted access to these pages, the crawl budget would be wasted, due to these having exactly the same styling and content, just with different product images present (on an e-commerce site). These pages provide little to nothing for Google and will, therefore, be crawled, potentially indexed and will be using the budget when it’s not necessary.
What Can We Do About It?
Working on the premise that RankBrain is the #1 factor to take into account here, we need to ensure that we provide it with the right information in order to benefit from the pages being crawled.
The first thing we need to do is be certain that we are only allowing Google to view the pages we DO WANT to be indexed, making sure we don’t allow any pages we DON’T WANT to be indexed, slip through the cracks.
There are a number of elements to check when looking preventing wasted crawl budget on a website that we can check, these include:
- Broken links
- Redirects
- Robots.txt
- NoIndexing
- Canonical Tags
- Page Speeds
- Pagination
- Sitemaps
Below we take a quick look at how each one of the above points can be easily optimised in order to prevent any crawl budget wastage.
Broken Links
As we know, Google uses links as “gateways” or “doors,” if you will, to navigate around the web to discover new pages. If these links are broken, then all they are doing is wasting the crawler’s time. It’s recommended that all reported 404 errors are rectified to help prevent the search engine from hitting a dead end.
Redirects
It’s common to see on many websites the use of redirects, either in singular use or daisy chaining, passing from one URL to another before reaching the final destination URL. Again, having too many redirects is generally bad practice SEO, but also wastes crawl budget, as the search engine needs to pass through these to understand where they land. It’s recommended that any daisy chaining redirect is revisited to keep them as simple as possible, making it easier for search engines to navigate through.
Robots.txt
Using a disallow directive in your websites Robots.txt is more of a last resort when optimizing crawl budget. We can implement a disallow rule to search result pages and paginated pages on a website to notify Google that we want these pages to be ignored. We would recommend implementing alternative methods before resorting to using this tool.
Meta NoIndex
The NoIndex tag is a useful tool to utilise when optimizing crawl budget. We can use this to tell search engines that we do not want a specific page to be blocked, but allow them to acknowledge that the page exists with the use of “follow.” This can be used on paginated, filter and search result pages, and can be removed at a later date (in the likely case that you discover a filtered page that holds high search volume). Google have claimed this doesn’t help much towards a cleanup, but it does help to some degree.
Canonical Tags
Canonical tags are commonly used to deal with duplicated or similar content to prevent search engines from demoting certain pages. We can also use this practice to help flag duplicated content, making it a little easier for search engines to understand the structure of a website; this, by telling Google what page they should show in their index, vs which similar pages they shouldn’t. Although it has been claimed that canonical tags do not offer much when looking to optimise crawl budget, they can still help.
Page Speeds
Similar to broken links, pages with high load times or pages that time out also create a dead end for search engines, restricting certain navigation and also wasting crawl budget. It’s recommended that these pages are addressed, tested and fixed based on what your findings are to improve the page speed and allow search engines to proceed to the page and acknowledge its content.
Pagination
Pagination is an important element of technical SEO and should be addressed at the start of any campaign. To ensure we make the most of our crawl budget, we need to make sure that the correct rel=next, prev directives are in place. Using this allows Google to see the paginated series as one logical sequence, indicating the relation between sequential URLs. This would also prevent “dead ends” for search engines when crawling the paginated pages.
Sitemaps
Search engines utilise sitemaps to find all pages on a website, particularly those that are particularly large sites with a lot of categories, product pages etc. There are a couple of things to keep in mind here. The first is that if there are any broken or incorrect links present within the sitemap, we are again sending the search engine to a dead end and wasting crawl budget.
Secondly, we can reduce the sizes of sitemaps to monitor key pages closely. For example, one sitemap containing 50,000 URLs and only 2000 indexed is an issue, but identifying those pages is a lot more difficult. We’d recommend increasing the number of XML sitemaps and decreasing the number of URLs in each, so for example, you have 20 sitemaps with 500 URLs in each, it’s easier to locate where there are issues. If you wanted to improve on this further, you can structure them based on categories.
Summary
To conclude, we can see that there are a lot of things that can be done in order to improve a websites crawl budget, it’s just a case of knowing what to implement, and where, in order to get the best return.
Not forgetting, in order to improve and build upon your crawl budget, it’s essential to continue to build high authority and equity pages. The general rule of thumb is that the higher the authority a page has, the more crawl budget search engines attribute to it (Confirmed by Matt Cutts).